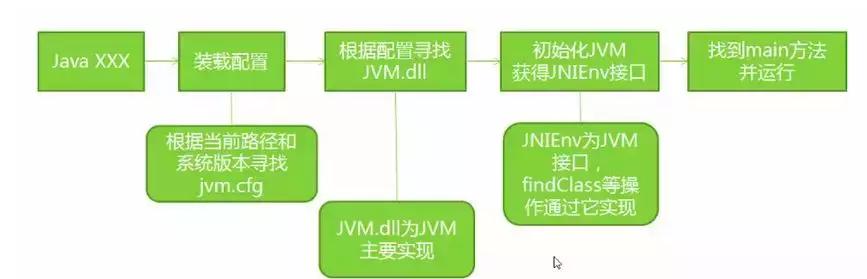
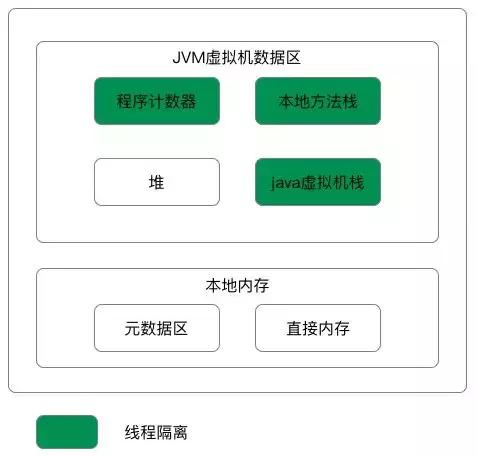
“灭霸”系统指的是Java虚拟机的概念。虚拟机是以软件方式模拟完整硬件系统功能,运行在完全隔离的环境中的完整计算机系统,是物理机的软件实现。
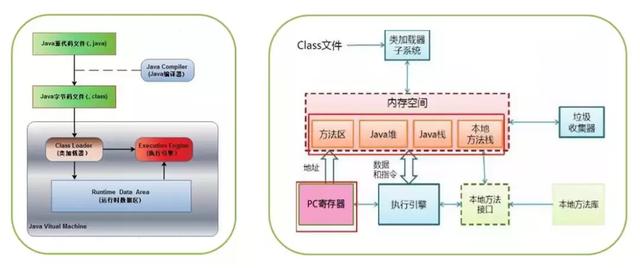
常见的虚拟机包括VMware、VirtualBox和Java虚拟机(简称JVM)。Java虚拟机的阵营包括Sun HotSpot VM、BEA JRockit VM、IBM J9 VM、Azul VM、Apache Harmony、Google Dalvik VM、Microsoft JVM等等。启动流程基本架构是,Java运行时编译源码(.java)成字节码,然后由jre来运行。jre是由java虚拟机(jvm)来执行的。对于Jvm来说,它会解析和执行字节码。JVM包括三个主要的子系统:1.类加载器子系统2.运行时数据区(内存)3.执行引擎。 类加载器子系统负责加载、连接(验证、准备、解析(可选))和初始化。Classloader及其子类负责执行类加载的任务。字节码文件加载:在硬盘上搜索并通过IO读取文件中的字节码
连接:执行校验、准备、解析(可选)步骤
校验:验证字节码文件的正确性
准备:为类的静态变量分配内存,并赋予默认值
解析:将符号引用转换为直接引用,类加载器将所引用的其他所有类一起加载
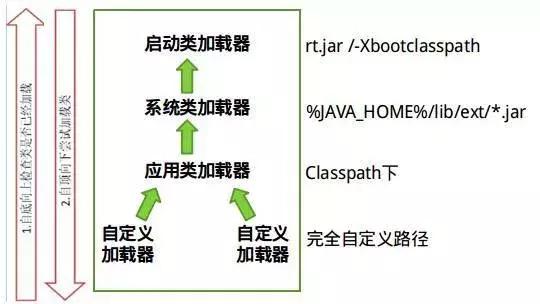
类加载器体系结构
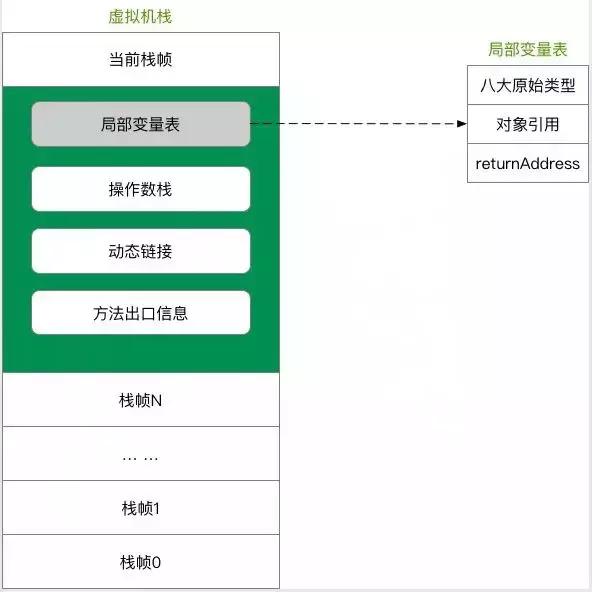
1.启动类加载器:负责加载JRE的核心类库,如位于jre目录下的rt.jarcharsets.1. BootStrap类加载器:负责加载JVM内置的类库,比如rt.jar等。\n2. 扩展类加载器:负责加载JRE的扩展目录ext中的JAR类包。\n3. 系统类加载器:负责加载ClassPath路径下的类包。\n4. 用户自定义加载器:负责加载用户自定义路径下的类包。\n双亲委派机制确保类加载的全盘负责委托。当一个ClassLoader加载一个类时,该ClassLoader将负责加载该类所依赖和引用的其他类,除非明确使用另一个ClassLoader。ClassLoader加载类时,遵循委托机制:首先委托父类加载器查找目标类,如果找不到,则在自己的路径中查找并加载目标类。运行时数据区包括堆,它在虚拟机启动时创建,用于存储几乎所有对象实例,包括常量池。当堆空间无法分配所需内存时,将抛出OutOfMemoryError异常。它也是废物回收管理的主要区域。可以使用 -Xmx 和 -Xms 参数分别设定最大堆和最小堆的大小。线程共享。Java栈是Java方法执行的内存模型,用于虚拟机执行Java方法。每个方法执行时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接和方法出口等信息。线程独占。Jvm对该区域设置了两种异常规范:
1,当线程请求的栈深度大于虚拟机栈所允许的深度时,将会抛出StackOverFlowError异常。如果虚拟机栈可以动态扩展,但无法申请到足够内存空间时,将会抛出OutOfMemoryError异常。可以通过JVM参数 -Xss 来指定栈的大小,栈的大小会决定函数调用的深度。本地方法栈是虚拟机用于执行native方法的一块内存区域,与Java虚拟机栈类似,但有一些额外的规范。不同种类的虚拟机可以在该区域自由部署和实现。线程独占。
 PC寄存器(程序计数器)
PC寄存器(程序计数器)
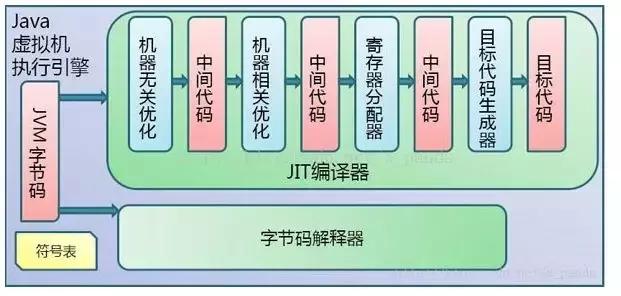
用于存储待执行指令的地址。程序的分支、循环、跳转、异常处理和线程恢复等功能,都是依赖于程序计数器寄存器的。线程独占。如果线程执行的是一个Java方法,那么pc寄存器中保存的是待执行指令的地址。如果正在执行的是一个本地方法,那么PC寄存器中就会空着。元数据区(Metaspace)取代了永久代(PermGen),本质上与永久代相似,都是实现JVM规范中的方法区。它们的区别在于元数据区不再受限于虚拟机的内存,而是利用本地内存。元数据区域经常被访问时,可能会导致内存溢出异常。元数据区的动态扩展,初始的XX:MetaspaceSize值为21MB,是其高水位线。一旦达到触发点,就会引发Full GC并卸载无用的类(即对应的类加载器不再存活),然后高水位线会被重置。GC释放后的内存空间决定了新的高水位线的值。如果可以利用的空间少,那么高水位线就会上升。如果释放的空间过多,那么高水位线将会下降。执行引擎负责读取运行时数据区的字节码并逐条执行。解释器能够快速解释字节码,但执行速度较慢,逐条解释执行。JIT编译器是指Just-In-Time编译器,它消除了解释器的不足。执行引擎会利用解释器将字节码转换为本地代码,并在发现重复的代码时使用JIT编译器来编译整个字节码。这段本地代码将被直接用于重复的方法调用,有助于提升系统性能。JIT的组成部分包括: 中间代码生成器(Intermediate Code Generator),负责生成中间代码。
代码优化器:负责对上述生成的中间代码进行优化。
目标代码生成器是用来生成机器代码或本地代码的组件。
分析工具(Profiler):一种特殊的组件,用于寻找热点(被多次调用的方法)
(3)垃圾回收器:负责收集和删除未被引用的对象。可以通过调用System.gc()来启动垃圾收集,但并不能保证它会被执行。JNI是本地方法接口,它用于与本地方法库进行交互,并为执行引擎提供所需的本地库。
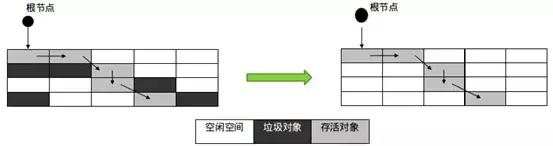
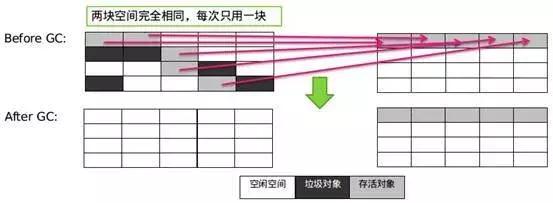
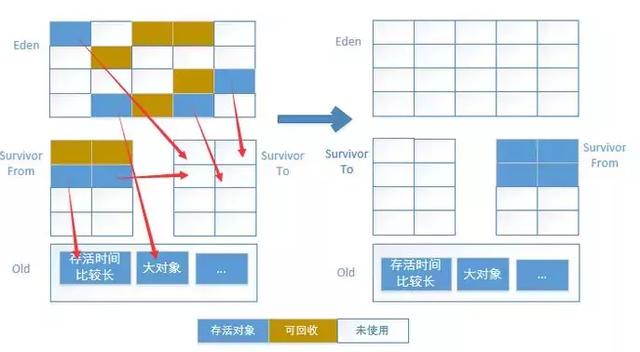
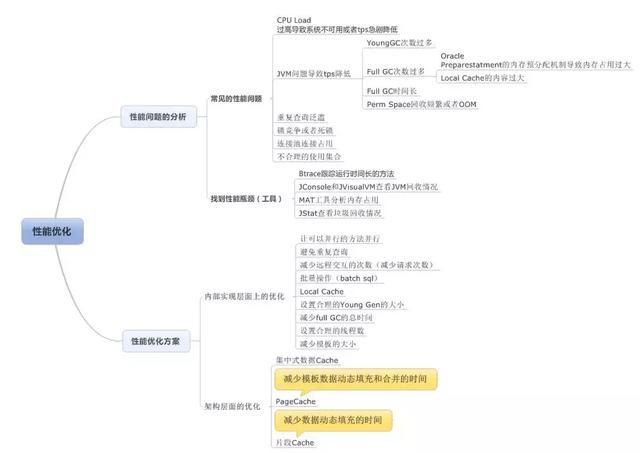
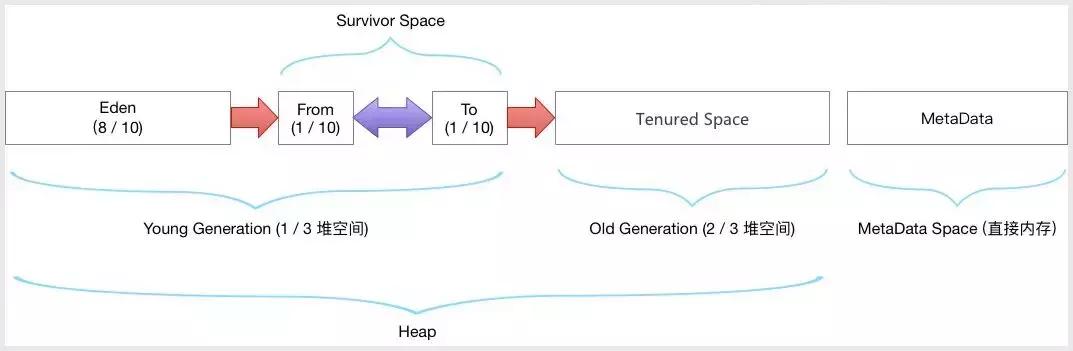
的本地方法库指的是执行引擎需要的本机库的集合。垃圾收集(GC)是一种自动管理内存的技术。通过标记和清除或复制的方式,垃圾收集器可以识别和回收不再被程序引用的对象,从而释放内存空间。关于如何识别垃圾对象和判定其是否可被回收,可以通过观察该对象是否有被程序引用的路径,如果没有任何引用路径指向该对象,那么可以认定为垃圾对象可以被回收。引用计数算法:为每个对象增加一个计数器,当有地方引用该对象时计数器加1,当引用失效时计数器减1。可以通过检查对象计数器是否为零来确定对象是否可以被垃圾回收。缺点:无法解决循环引用的问题。 根搜索算法,也称为可达性分析法,是通过将"GC ROOTs"对象作为搜索起点,然后向下搜索引用,所经过的路径被称为引用链。判断对象是否可被回收,要看它是否有到达引用链的路径。可以作为GC ROOTs的对象有:虚拟机栈中引用的对象,方法区中类静态属性引用的对象,方法区中常量引用的对象,本地方法栈中JNI引用的对象。在Java中,堆是GC收集垃圾的主要区域,GC分为两种:Minor GC和Full GC(也称为Major GC)。Minor GC 是指在新生代 (Young Gen) 空间不足时触发的垃圾收集过程。由于在 Java 中,大部分对象通常不需要长时间存活,所以新生代是垃圾收集频繁的区域,因此使用了复制算法。Full GC:当老年代(Old Gen)空间不足或元空间达到高水位线时,系统会执行收集动作。由于这些区域存放了大对象和长时间存活的对象,它们占用了大量的内存空间,并且回收效率较低,因此采用标记-清除算法进行垃圾回收。垃圾收集算法根据回收策略可以分为:标记-清除算法、标记-整理算法和复制算法。
对待垃圾回收的方法可以分为:增量收集算法和分代收集算法
1.增量收集:这是一种实时垃圾回收算法,即在应用程序运行过程中进行垃圾回收,理论上能够解决传统分代方式带来的问题。增量收集将堆空间划分成一系列内存块,在使用时先部分使用,垃圾收集时将之前使用过的存活对象移到未使用的空间,实现边使用边收集的效果,避免了传统分代方式整个使用完了再暂停回收的情况。
2. 分代收集:(商用默认)根据对象的生命周期划分为新生代、老年代和元空间,采用不同的算法对不同生命周期的对象进行回收。

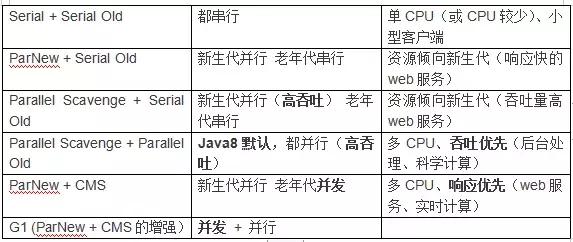
根据系统线程的分类,垃圾回收可以分为串行收集算法、并行收集算法和并发收集算法。
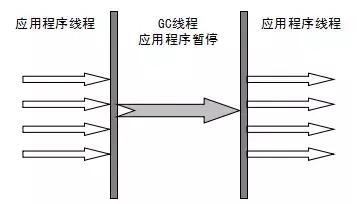
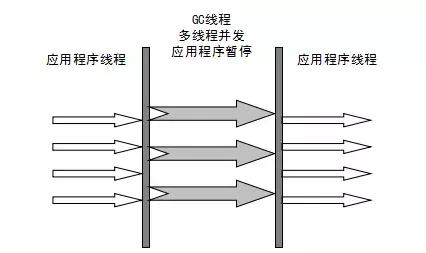
1. 串行收集:采用单线程执行垃圾回收工作,易于实现,效率较高。存在的不足包括:1. 无法充分利用多处理器的优势;2. 需要暂停用户线程{X}{N}{X}2;3. 并行收集:采用多线程处理垃圾回收任务,速度更快,效率更高。理论上,CPU的数量越多,就越能够展现并发收集器的优势。问题:需要暂停用户线程x次。同时进行并发收集:垃圾线程和用户线程同时工作。系统在进行垃圾回收时无需暂停用户线程
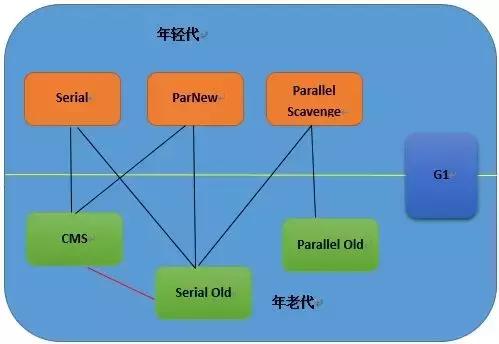
GC收集器
Serial Old收集器的主要目标是对老年代进行收集,使用标记-整理算法,实现简单高效,但可能会导致停顿。
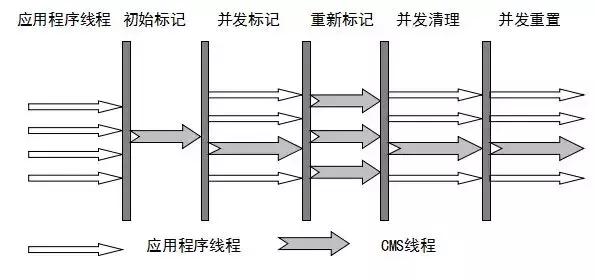
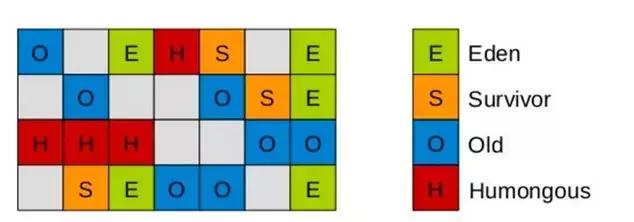
2. ParNew收集器是Serial的多线程版本,用于新生代,使用复制算法。采用多线程进行垃圾收集,使用并行收集器并注重响应优先。 Parallel Scavenge是一种专为新生代设计的多线程垃圾收集器,采用复制算法,并行收集,强调高吞吐量。可以调整吞吐量和停顿时间,换言之,吞吐量等于运行用户代码时间除以(运行用户代码时间加上垃圾收集时间)。Parallel Old收集器是Parallel Scavenge收集器的老年代版本,采用多线程和标记-整理算法。4. CMS(Current MarkSweep)是一种专门针对老年代的收集器,其目标是尽可能缩短回收停顿时间。CMS是一种并发收集器,采用标记-清除算法。当新生代占用达到特定比例时,G1的新生代类似于ParNew,采用复制算法进行收集。老年代和CMS有相似之处,但它采用了标记-整理算法。因此,它是一种并行和并发的收集器,能够充分利用多个CPU和多核环境。是的,GPT-3.5在某些情况下可以用于建立可预测的停顿时间模型。停顿时间模型可以帮助预测人类在语言交流中的停顿位置和时长。这在语音识别、自然语言处理和其他相关领域中可能会很有用。如果您需要更多关于此主题的信息,请告诉我,我将乐意为您提供帮助。与CMS收集器相比,G1收集器具有以下特点:\n1. 空间整合,采用标记-整理算法,不会产生内存空间碎片。将大对象分配到专门用来存放短期巨型对象的Humongous区,而不是直接分配到老年代,可以避免由于无法找到连续空间而提前触发下一次GC,因此也可以减少Full GC的大量开销。当年轻代没有可用空间时,老年代无法转移对象;或者当没有连续的空间用于存放大对象时,就会触发Full GC,造成巨大的开销,应该尽量避免。2. G1和CMS都致力于实现可预测的停顿时间,以降低停顿时间。不过,G1收集器不仅追求低停顿,还能建立可预测的停顿时间模型。这种模型允许使用者明确指定,在N毫秒的时间内,垃圾收集所消耗的时间不得超过N毫秒,几乎达到了Java实时系统(RTSJ)级别的垃圾收集器。3.G1对Java堆进行了改进,将其划分为多个大小相等的独立区域,称为Region。尽管仍然存在新生代和老年代的概念,但它们不再是物理上的隔离,而是由多个不连续的Region组成的集合。
常用
GC日志的解读
新生代GC日志样例:[GC [PSYoungGen: 8192K->1000K(9216K)] 16004K->14604K(29696K),耗时0.0317424秒] [Times: user=0.06 sys=0.00,real=0.03秒] [GC [PSYoungGen: 9192K->1016K(9216K)] 22796K->20780K(29696K), 0.0314567秒] [Times: user=0.06 sys=0.00, real=0.03秒] [Full GC [PSYoungGen: 8192K->8192K(9216K)] [ParOldGen: 20435K->20435K(20480K)] 28627K->28627K(29696K),[元空间: 8469K->8469K(1056768K)], 0.1307495秒] [时间: 用户=0.50系统=0.00, 实际=0.13 秒] [完全GC [PSYoungGen: 8192K->8192K(9216K)] [ParOldGen: 20437K->20437K(20480K)] 28629K->28629K(29696K), [元空间: 8469K->8469K(1056768K)]0.1240311秒] [时间: 用户=0.42 系统=0.00, 实际=0.12秒]
常见异常
StackOverflowError:(栈溢出) OutOfMemoryError: Java堆空间不足{堆空间不足} OutOfMemoryError: GC超过最大运行时间限制 (GC花费的时间超过 98%,并且GC回收的内存少于2%的情况下。 GC参数包括:
 堆栈设置如下:
-Xss:每个线程的栈大小
-Xms:初始堆大小,默认为物理内存的1/64
-Xmx:最大堆大小,默认为物理内存的1/4
-Xmn:新生代大小
-XX:NewSize:设置新生代初始大小
-XX:NewRatio:默认为2,表示新生代占年老代的1/2,占整个堆内存的1/3。
-XX:SurvivorRatio的默认值是8,表示一个survivor区占用Eden内存的1/8,即新生代内存的1/10。
-XX:SurvivorRatio: 默认值为8,表示一个survivor区占用Eden内存的1/8,即新生代内存的1/10。
-XX:MaxMetaspaceSize: 设置元空间的最大可允许大小,默认情况下没有限制,JVM Metaspace会进行动态扩展。垃圾回收统计信息:\n-XX:+PrintGC:打印GC事件。\n-XX:+PrintGCDetails:打印详细的GC信息。\n-XX:+PrintGCTimeStamps:打印GC的时间戳。\n-Xloggc:filename:将GC日志记录到指定文件中。\n收集器设置:\n-XX:+UseSerialGC:设置串行收集器。\n-XX:+UseParallelGC:设置并行收集器。\n-XX:+UseParallelOldGC:设置并行老年代收集器。\n-XX:+UseParNewGC:在新生代使用并行收集器。\n-XX:+UseParalledlOldGC:设置并行老年代收集器。\n-XX:+UseConcMarkSweepGC:设置CMS并发收集器。\n-XX:+UseG1GC:设置G1收集器。\n-XX:ParallelGCThreads:设置用于垃圾回收的线程数。\n并行收集器设置:\n-XX:ParallelGCThreads:设置并行收集器收集时使用的CPU数。线程的并行收集数量。并行收集线程数:
\n-XX:MaxGCPauseMillis:限制并行收集的最大暂停时间为
毫秒\n-XX:GCTimeRatio:设置垃圾回收所占程序运行时间的百分比1/(1+n)是用于CMS收集器的设置x。\n-XX:+UseConcMarkSweepGC用于启用CMS并发收集器。\n-XX:+CMSIncrementalMode用于启用增量模式。适用于只有一个CPU的情况。
-XX:ParallelGCThreads用于指定并发收集器在并行收集新生代时使用的CPU数量。可同时运行的线程数。
-XX:CMSFullGCsBeforeCompaction: 设置进行多少次CMS垃圾回收后,进行一次内存压缩。 \n
-XX:+CMSClassUnloadingEnabled: 允许回收类元数据。 \n
-XX:UseCMSInitiatingOccupancyOnly: 表示只有在到达阀值时才进行CMS回收。 \n
-XX:+CMSIncrementalMode: 设定为增量模式。适用于单CPU情况的参数如下:\n-XX:ParallelCMSThreads: 确定CMS的线程数量\n-XX:CMSInitiatingOccupancyFraction: 设置CMS收集器在老年代空间使用多少后触发\n-XX:+UseCMSCompactAtFullCollection: 设置CMS收集器在完成垃圾收集后是否进行一次内存碎片的整理\nG1收集器设置如下:\n-XX:+UseG1GC: 使用G1收集器\n-XX:ParallelGCThreads: 指定GC工作的线程数量\n-XX:G1HeapRegionSize: 指定分区大小为1MB到32MB如果没有指定堆大小(必须是2的幂),系统会默认将整个堆划分为2048个分区。另外,-XX:GCTimeRatio参数用来设置垃圾收集器的时间比率,取值范围是0到100的整数,默认值是9。当值为n时,系统将用于垃圾收集的时间不会超过1/(1+n)。 -XX:MaxGCPauseMillis: 目标最大暂停时间 (默认200毫秒) -XX:G1NewSizePercent: 新生代空间的初始分配比例 (默认整堆的5%) -XX:G1MaxNewSizePercent: 新生代空间的最大分配比例 -XX:TargetSurvivorRatio: Survivor区的空间利用率 (默认50%) -XX:MaxTenuringThreshold: 最大晋升阈值 (默认15) -XX:InitiatingHeapOccupancyPercen: 触发标记循环的整堆占用比例阈值 (默认45%)执行超过则启用混合收集\n-XX:G1HeapWastePercent:堆废物百分比(默认为5%)\n-XX:G1MixedGCCountTarget:参数混合收集的最大总次数(默认为8)\n性能分析和监控工具\nJps:Java虚拟机进程状态工具\nJstat:Java虚拟机统计信息监视工具\nJinfo:Java虚拟机配置信息工具\nJmap:Java内存映像工具\nJhat:Java虚拟机堆转储快照分析工具\nJstack:Java堆栈跟踪工具\nJConsole:Java监视与管理控制台\nVisualVM:故障处理工具
堆栈设置如下:
-Xss:每个线程的栈大小
-Xms:初始堆大小,默认为物理内存的1/64
-Xmx:最大堆大小,默认为物理内存的1/4
-Xmn:新生代大小
-XX:NewSize:设置新生代初始大小
-XX:NewRatio:默认为2,表示新生代占年老代的1/2,占整个堆内存的1/3。
-XX:SurvivorRatio的默认值是8,表示一个survivor区占用Eden内存的1/8,即新生代内存的1/10。
-XX:SurvivorRatio: 默认值为8,表示一个survivor区占用Eden内存的1/8,即新生代内存的1/10。
-XX:MaxMetaspaceSize: 设置元空间的最大可允许大小,默认情况下没有限制,JVM Metaspace会进行动态扩展。垃圾回收统计信息:\n-XX:+PrintGC:打印GC事件。\n-XX:+PrintGCDetails:打印详细的GC信息。\n-XX:+PrintGCTimeStamps:打印GC的时间戳。\n-Xloggc:filename:将GC日志记录到指定文件中。\n收集器设置:\n-XX:+UseSerialGC:设置串行收集器。\n-XX:+UseParallelGC:设置并行收集器。\n-XX:+UseParallelOldGC:设置并行老年代收集器。\n-XX:+UseParNewGC:在新生代使用并行收集器。\n-XX:+UseParalledlOldGC:设置并行老年代收集器。\n-XX:+UseConcMarkSweepGC:设置CMS并发收集器。\n-XX:+UseG1GC:设置G1收集器。\n-XX:ParallelGCThreads:设置用于垃圾回收的线程数。\n并行收集器设置:\n-XX:ParallelGCThreads:设置并行收集器收集时使用的CPU数。线程的并行收集数量。并行收集线程数:
\n-XX:MaxGCPauseMillis:限制并行收集的最大暂停时间为
毫秒\n-XX:GCTimeRatio:设置垃圾回收所占程序运行时间的百分比1/(1+n)是用于CMS收集器的设置x。\n-XX:+UseConcMarkSweepGC用于启用CMS并发收集器。\n-XX:+CMSIncrementalMode用于启用增量模式。适用于只有一个CPU的情况。
-XX:ParallelGCThreads用于指定并发收集器在并行收集新生代时使用的CPU数量。可同时运行的线程数。
-XX:CMSFullGCsBeforeCompaction: 设置进行多少次CMS垃圾回收后,进行一次内存压缩。 \n
-XX:+CMSClassUnloadingEnabled: 允许回收类元数据。 \n
-XX:UseCMSInitiatingOccupancyOnly: 表示只有在到达阀值时才进行CMS回收。 \n
-XX:+CMSIncrementalMode: 设定为增量模式。适用于单CPU情况的参数如下:\n-XX:ParallelCMSThreads: 确定CMS的线程数量\n-XX:CMSInitiatingOccupancyFraction: 设置CMS收集器在老年代空间使用多少后触发\n-XX:+UseCMSCompactAtFullCollection: 设置CMS收集器在完成垃圾收集后是否进行一次内存碎片的整理\nG1收集器设置如下:\n-XX:+UseG1GC: 使用G1收集器\n-XX:ParallelGCThreads: 指定GC工作的线程数量\n-XX:G1HeapRegionSize: 指定分区大小为1MB到32MB如果没有指定堆大小(必须是2的幂),系统会默认将整个堆划分为2048个分区。另外,-XX:GCTimeRatio参数用来设置垃圾收集器的时间比率,取值范围是0到100的整数,默认值是9。当值为n时,系统将用于垃圾收集的时间不会超过1/(1+n)。 -XX:MaxGCPauseMillis: 目标最大暂停时间 (默认200毫秒) -XX:G1NewSizePercent: 新生代空间的初始分配比例 (默认整堆的5%) -XX:G1MaxNewSizePercent: 新生代空间的最大分配比例 -XX:TargetSurvivorRatio: Survivor区的空间利用率 (默认50%) -XX:MaxTenuringThreshold: 最大晋升阈值 (默认15) -XX:InitiatingHeapOccupancyPercen: 触发标记循环的整堆占用比例阈值 (默认45%)执行超过则启用混合收集\n-XX:G1HeapWastePercent:堆废物百分比(默认为5%)\n-XX:G1MixedGCCountTarget:参数混合收集的最大总次数(默认为8)\n性能分析和监控工具\nJps:Java虚拟机进程状态工具\nJstat:Java虚拟机统计信息监视工具\nJinfo:Java虚拟机配置信息工具\nJmap:Java内存映像工具\nJhat:Java虚拟机堆转储快照分析工具\nJstack:Java堆栈跟踪工具\nJConsole:Java监视与管理控制台\nVisualVM:故障处理工具